| 您现在的位置:首页 > 技术资料 |
|
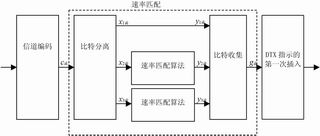
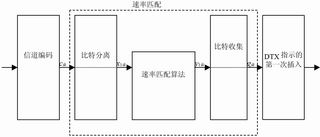
WCDMA速率适配算法的FPGA实现 引言 随着因特网爆炸性的增长以及各种无线业务需求的增加,传统的无线通信网已经越来越无法适应人们的需要。因此,以大容量、高数据率和承载多媒体业务为目的的第三代移动通信系统(IMT-2000)应运而生。码分多址(CDMA)由于其良好的抗噪性、保密性和简单性等优点而成为第三代移动通信的主流。主要方案包括欧洲标准WCDMA,美国标准CDMA-2000和中国标准TD-SCDMA。 和传统的CDMA系统相比,第三代移动通信的最大特点在于可支持具有不同QoS的变速率的多种业务,这便要求其具有将各种无线媒体业务复接在一起传输的能力。为了达到这一目标,WCDMA采用了一种比较完善的业务复接方案,各种业务须经过一套复杂的编码复接流程才能进行扩频调制,占用尽可能少的码道以恒定的功率发送。这样就最大限度地减少了码道间串扰,降低了对功放线性程度的要求。图1所示的是WCDMA下行链路编 码复接方案流程图。而速率适配算法是业务复用方案的核心算法,如何设计有效的算法实现方案,是业务复用方案设计的关键环节。
图1 下行链路编码复接方案
速率适配算法描述
一条传输信道上不同的传输时间间隔中的比特数有可能不一样,但是上下行链路都对传输的比特率有一定的要求:下行链路中如果比特数低于最小值的就会被中断;上行链路中各传输时间间隔的比特数不同,但需要保证第二次交织后的总比特率等于所分配的专用物理信道的总比特率。因此需要重复或者凿去传输信道上的一些比特。速率适配就是指在传输信道上的数据比特被凿孔(Puncturing)或重复(Repeating),以便使信道映射时达到传输格式所要求的比特速率。“凿孔”是按照一定的算法凿去某些位置的比特;“重复”则按照一定的算法在某些位置插入重复比特。 速率匹配前的比特记为:xi1,xi2,xi3,k,xixi 其中 i 为 TrCH 号,速率匹配参数为Xi, eini, eplus, 和eminus。 eini:初始化误差,算法中误差e的初始值; eminus:相减误差,算法中误差e的相减值; eplus:相加误差,算法中误差e的相加值; N:数据量,即速率适配前的数据量。 速率匹配的规则如下: if 要执行“凿孔”操作 e="eini" 初始化目前的与要求的凿孔比例之间的偏差 m="1" 当前比特索引序号 do while m <= N e="e"-eminus 修改误差 if e <= 0 then 检查m是否是应该凿掉的比特序号 凿掉该比特xi,m e="e"+eplus 更改误差 end if m="m"+1 进行下一个比特的判断 end do e = eini 初始化目前的与要求的凿孔比例之间的偏差 m = 1 当前比特索引序号 do while m <= N e = e - eminus 修改误差 do while e <= 0 检查比特m 是否是应被重复的比特序号 重复比特 xi,m e = e + eplus 更改误差 end do
end do end if 该适配算法对于上行链路和下行链路都是适用的。3GPP协议中规定了“凿孔”和“重复”算法的使用对象与范围。Turbo编码后的系统比特不允许凿去,因此如果对Turbo编码后的数据进行“凿”操作,则首先应将系统比特和校验比特区分开,仅对其中的校验比特进行“凿”操作;然而Turbo编码后的数据如果进行“重复”以及卷积编码后数据进行“凿”或“重复”都不区分系统比特与校验比特。上述情况的速率匹配见图2及图3。
图2 下行链路Turbo编码比特凿孔时TrCH的速率适配
图3 下行未编码和卷积编码以及重复的Turbo编码的TrCH的速率匹配 另外,协议给出的确定参数的算法依编码方式及链路的不同而不同。也就是说,Turbo编码与卷积编码、下行链路与上行链路在确定适配参数的算法上有区别。具体的确定算法可以参考3G相应的协议。 速率适配的FPGA实现 通过对编码复接的方案研究发现,直接根据协议流程对数据流各个步骤(一共大约11个步骤)直接进行处理将会大大增加系统复杂度,这样每个步骤之间都需对数据进行缓存,而移动环境下系统支持的最高速率可达384Kbps,对于TTI=20ms的业务,平均每步需要的缓存为7.68K,所需要的总存储量是巨大的。而且这中间,数据流频繁的写入读出所导致的处理时延也是难以忍受的。因此,如果将某些步骤合并起来,就能减少不必要的数据存取工作,从而节省存储量,缩短处理延时。 上行链路的速率匹配按10ms数据帧为单位进行,而下行链路则是以TTI为单位针对一个无线帧的数据比特进行的。虽然算法上一致,但是考虑到上下行各自的步骤合并情况,在实际处理上还是有很大区别的。下面以下行144Kb/s速率适配为例介绍一下其FPGA的实现方法。 144Kb/s速率适配过程大致分为两个模块:凿图样产生模块和保留比特搬移转换模块。在实现过程中,用到的存储资源是两个RAM―一个用来存“凿”图样、另一个用来存原来的数据,两个DCFIFO(双时钟FIFO)用来存比特收集后的两帧数据。 凿孔图样产生模块 由于144Kb/s业务信道编码用的是Turbo编码,凿孔时只针对两个分量编码器输出的校验比特,因此需先进行比特分离再分块进行凿孔操作(系统比特块自动保留不进行凿孔操作)。我们采用了一种凿孔图样控制方式,所有待速率适配比特都对应一个P比特,P=1表示凿去,P=0表示保留,以此种方式产生凿孔图样来控制保留比特的搬移。具体实现框图如图4所示。主要硬件结构包括一个加法器、一个减法器、一个数值比较器、一个计数器和一个选通控制模块及参数初始化模块。
图4 凿孔图样产生 该结构工作过程如下:首先,比特分离和参数初始化模块主要完成模块计数和eini、eminus、eplus等参数的初始化设置。 在减法器端,当前误差值e减去eminus,该数值同时送给数值比较器和选通控制模块。减法器的输出结果和0值作比较,如果结果小于零则记P比特为1;如果结果大于零则记P比特为0,同时将减法器的输出结构作为当前加法器的A端输入值。P比特则在选通控制模块产生的读写使能、地址信号线的驱动下写入Punc_ram。另外用一个计数器来对比特数进行记录,以控制整个流程的结束时刻。系统时钟为8倍码片时钟,计数器和Punc_ram都采用同步控制,加法器、减法器及比较器都不采用同步时钟延时。
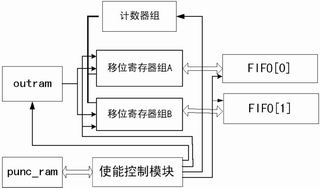
保留比特搬移转换模块 凿图样产生以后,接下来的操作就是保留比特的搬移和转换,并进行第一次交织和无线帧分段。按照3GPP协议,对于TTI=20ms的144Kb/s业务,其交织模式是<0,1>,亦即顺序输出。
图5 保留比特搬移转换
实现的流程图如图5。假定TURBO编码后待的比特流存在out_ram中,这里进行的操作关键是凿孔图样的读出和out_ram的读出应该是同步一致进行(在同一个时钟上升沿开始),用Punc_ram的输出来作为积攒比特的使能信号。用移位寄存器组和计数器实现比特积攒,每等到满16bit时,就进行串并转换,同时产生一个fifo写使能脉冲,把一个字的内容写入fifo;等到满一帧(复接前的数据帧)的时候,转向对下一个fifo进行写操作。到一个数据帧4205bit结束时,积攒比特不满16的补零表示,串并转换为一个字写入fifo。 资源使用和时延分析 按照上面的实现方式,主要占用的是存储资源,现代FPGA中的ESB(嵌入式系统块)可以很容易地实现各种类型的存储模块,包括双端口RAM、ROM、FIFO及CAM块。下面主要进行的是时延分析。 按照上面的流程可以大致估算一个比特从“凿孔”图样产生到比特搬移完成所用的时间。所选工作时钟速率为8倍码片速率3.84MHz,一个时钟周期约为32.4ns。凿孔图样模块中的加法器、减法器、选通控制大概需要3个时钟周期,9516个凿孔图样的产生需要大致925ns;保留比特搬移模块主要是数据比特的直接搬移,对于最后一个比特而言,假定它是保留比特,从搬移开始到最终写入FIFO,经过了大致9516+16=9532个时钟周期,耗时大约308ns。对整个流程用MAXPUSII仿真,总共耗时1.336ms,考虑到中间的缓冲控制和使能控制延迟,仿真结果和计算值大致吻合。对于TTI=20ms的业务,完全满足处理要求。
结语 WCDMA系统的电路型数据业务(64K)和分组型数据业务(144K、384K)可以实现对多媒体业务的承载,但由于基带数据处理量大、比特搬移操作明显,编码复接中的核心算法之一速率适配算法我们采用了FPGA实现,并且适当合并了前后步骤,大大缩短了处理时间,使系统达到了很高的吞吐量和处理速度,完全满足3GPP协议规范的要求。在实际实施中被证明是可行的。此外,文中提出的模块合并、产生凿孔图样进行比特积攒搬移的思想同样可以适合未来更复杂的编码复接方案。
| |||||||||||||||||